
企業のデジタル化が進む中、製造業が競争力を維持するには膨大なデータの効果的な活用が欠かせません。
従来のデータ管理システムでは対応しきれない多様なデータを一元管理するソリューションとして、データレイクが注目を集めているのです。
またAI技術との融合によって、さらなる価値創出が期待されています。
本記事では、データレイクの基本概念から実際の導入ステップ、成功事例まで詳しく解説していきます。
目次
データレイクとは?
データレイクは、多様な形式のデータを一元管理できる大規模なデータ保管庫で、製造現場から生まれる様々なデータを、加工せずそのままの形で保存できます。工場のセンサー情報や生産記録だけでなく、画像や動画といった非構造化データも取り込めるため、製造業の経営者にとって貴重な情報源となります。
従来のデータベースでは事前に形式を決める必要がありましたが、データレイクではそのような制約がなく、後から様々な分析に活用できるのです。この仕組みにより、製品の品質管理や工場間の連携強化、生産性向上など多彩な活用が可能になります。
特に製造業では、複数工場の情報を一元管理して「工場のオーケストレーション」と呼ばれる効率的な生産体制を実現する基盤としても注目されています。
データレイクを導入することで、経営判断に必要な情報をリアルタイムで把握し、競争力強化につなげられるでしょう。
データレイクとデータウェアハウスの3つの違い
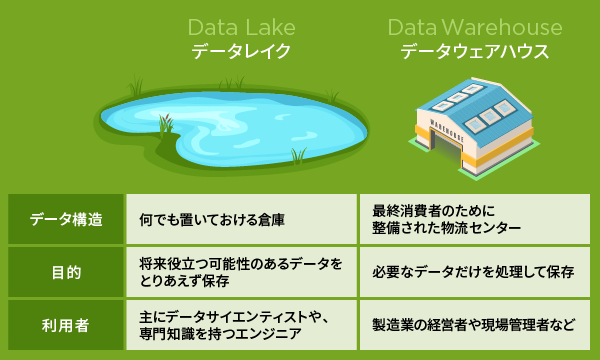
データレイクと比較される言葉で「データウェアハウス」がありますが、両者には明確な違いがあります。
- データ構造
- 目的
- 利用者
順番に解説していきます。
違い1:データ構造
データレイクは、多様な形式のデータを加工せずそのままの状態で保存できる大規模なデータ保管庫です。
製造現場のセンサー情報から画像・動画まで、あらゆるデータをそのままの形で蓄積可能なため、データ容量は大きくなりがちです。
一方、データウェアハウスは目的に合わせて処理され、整理された状態のデータのみを保存します。データウェアハウスは「物流センター」のように整備された環境で、検索性に優れていますが、データの整理・整頓にコストがかかります。
データレイクが「何でも置いておける倉庫」だとすれば、データウェアハウスは「最終消費者のために整備された物流センター」と考えると理解しやすいでしょう。
違い2:目的
データレイクは利用目的が明確に定義されていないデータも格納できる柔軟なシステムです。
将来役立つ可能性のあるデータをとりあえず保存しておくことができるため、現代のような変化の激しい社会情勢においては大きな価値があります。特に製造業など、今は必要ないと思われるデータが将来必要になるケースも増えてきており、データレイクの需要が高まっています。
対照的に、データウェアハウスは特定の目的のために厳密に構造化・フィルタリングされたデータを保管します。
必要なデータだけを処理して保存するため、ストレージ容量の節約にもつながりますが、当初想定していなかった分析には対応しづらいという特徴があります。
違い3:利用者
データレイクには未処理の非構造化データが格納されているため、一般のユーザーには扱いづらい特徴があります。
主にデータサイエンティストや、専門知識を持つエンジニアが専門ツールを用いて分析することが一般的です。製造業においては工場のセンサーデータや画像分析など、専門的な分析が必要な場面で活用されています。
一方、データウェアハウスは処理済みのデータを扱い、チャートやテーブルなどで視覚的に理解しやすい形式で提供されます。
製造業の経営者や現場管理者など、データ分析の専門知識がなくても、必要な情報を簡単に取り出せるよう設計されているのが特徴です。
製造業がデータレイクを導入する3つのメリット
製造業がデータレイクを導入するメリットは、主に以下の3点です。
- 工場間データ連携による生産効率の向上
- 品質管理とリアルタイム経営判断の実現
- 柔軟なデータ活用によるコスト削減
順番に見ていきましょう。
メリット1:工場間データ連携による生産効率の向上
データレイクを導入すると、複数の工場間でデータを標準化し、効率的に共有できるようになります。
各工場のセンサー情報や生産記録を一元管理することで、工場間のデータの内容や品質のギャップをなくせる利点があります。生産管理本部がデータ統括を行えば、工場間の連携がスムーズになり、生産効率が大幅に向上するでしょう。
データの標準化により工場間の情報ギャップを解消できるのです。
メリット2:品質管理とリアルタイム経営判断の実現
製造工程のセンサーデータをデータレイクに蓄積すると、品質トレンドの把握や異常検知が可能になります。
不良品の発生を予測し、事前に対策を打てるのが製造業にとって大きな強みとなるでしょう。
生産進捗をリアルタイムで把握できるため、経営層が現場の状況を即座に確認できるようになります。従来は月1回や週1回だった情報共有が、データレイクによってリアルタイムに変わり、素早い経営判断ができるのです。
生産現場の問題を経営がタイムリーにサポートすることで、問題解決のスピードも向上します。
メリット3:柔軟なデータ活用によるコスト削減
データレイクの最大の特徴は、データの形式を問わずそのままの形で保存できる点です。
構造化データも非構造化データも同様に格納でき、部門間の壁を越えた情報共有が容易になるメリットがあります。機械の稼働データやメンテナンス情報を活用すれば、故障を予測し生産ラインの停止時間を最小限に抑えられます。
サプライチェーン全体のデータ分析により、需要予測の精度向上や余剰在庫の削減も実現可能となりました。
多くの企業では、データレイクの活用によって新しい独自AIのアルゴリズム開発など、競争力強化につながる成果も出ています。
製造業におけるデータレイク導入の成功事例3選
ここからは、製造業におけるデータレイク導入の成功事例を3つ紹介していきます。
順番に見ていきましょう。
事例1:総合機械メーカーのグループ全体データ活用基盤の構築
一般産業機械から精密機械、建設機械まで幅広い製品を扱う総合機械メーカーでは、グループ内に蓄積されるデータを積極的に活用するためのデータレイクを構築しました。
同社はまず、データのビジュアル分析プラットフォームを導入し、ユーザーが自分で必要なデータを分析できる環境づくりからスタートしています。
データレイク構築の検証から始め、グループ内にある膨大なデータを効率的に蓄積し、必要な情報を簡単に取り出せる仕組みを実現しました。
従来はデータが各部門に分散していたため情報共有が難しかった問題が解消され、経営層の意思決定スピードが向上したと言えるでしょう。グループ企業全体でデータを共有することで、製品開発から生産、販売までの一貫したデータ活用が可能になり、業務効率化につながっています。
事例2:精密機器メーカーの部門間データ連携強化
大手精密機器メーカーは、クラウドサービスを活用してデータレイクを構築し、部門間のデータ共有を強化することに成功しました。
製造部門と営業部門がリアルタイムでデータを共有できるようになったことで、製品の需要予測精度が向上し、在庫管理の最適化が実現しました。
従来は部門ごとに独立したシステムでデータを管理していたため、情報の共有に時間がかかっていた課題が解消されています。各部門が必要なデータに迅速にアクセスできる環境が整ったことで、業務効率が大幅に改善されました。
意思決定のスピードアップも実現し、市場の変化に素早く対応できる体制が整ったことで、競争力強化につながっています。
事例3:自動車部品メーカーの製造DX基盤構築によるコスト削減
熱交換技術を扱う自動車部品メーカーでは、多様化する顧客ニーズやカーボンニュートラルへの対応のため、データレイクを中心とした製造DX基盤を構築しました。
IoTデータや調達・物流データなど、製造業特有の大量かつ細かいデータを一元管理できる環境を整備したのです。データをブロンズ・シルバー・ゴールドとレイヤー分けし、段階的に加工・分析する仕組みを採用したことで、データの質と活用効率が向上しました。
この取り組みにより開発工数が削減され、生産ラインの管理業務でも工数削減に成功しています。
データレイク導入の5つのステップ
製造業にデータレイクを導入するまでの手順は、大きく以下の5ステップに分けられます。
- ビジネス課題と目標の明確化
- データの棚卸しと収集計画の立案
- ストレージの選定と環境構築
- データの取り込みと変換プロセスの設定
- セキュリティ対策とデータガバナンスの確立
順番に解説していきます。
ステップ1:ビジネス課題と目標の明確化
まずは、製造現場のどの課題を解決したいかを明確にすることから始めましょう。
漠然と「データを活用したい」という思いだけでは失敗しやすいため、品質管理の向上なのか、生産効率の改善なのか、具体的な目標設定が必要です。例えば「異常率を5%削減する」「生産計画と実績の差異を半減させる」など、数値目標を設定すると良いでしょう。
製造業では特に、
- 工場間のデータ連携による生産効率向上
- 品質管理の革新
- リアルタイム経営判断の実現
などが主な目的となることが多いです。
この段階で経営層と現場責任者が集まり、導入によって得られる具体的なメリットを共有しておくことが大切です。
ステップ2:データの棚卸しと収集計画の立案
製造現場には様々なデータが存在しているため、どのようなデータがどこに存在するのかを把握する必要があります。
- 生産設備のセンサーデータ
- ERP/MESシステムのデータ
- 品質検査記録
など、製造業特有のデータを洗い出していきましょう。
データの形式や更新頻度、重要度を整理し、どのデータから優先的に取り込むかの計画を立てます。
基幹システムだけでなく、各部門が個別に保有するエクセルデータなども統合対象として精査することが重要です。
最初から全てのデータを取り込もうとせず、重要度の高いデータから段階的に進めることで、プロジェクトの成功率が高まります。
ステップ3:ストレージの選定と環境構築
データレイクの格納先となるストレージを選定します。
選択肢としては、
- Hadoop
- クラウドサービスのAmazon S3
- Azure Data Lake Storage
などが挙げられます。
製造業では扱うデータ量が多いため、将来的な拡張性を考慮してクラウドベースのストレージを選ぶと良いでしょう。
特に複数工場のデータを統合する場合は、スケーラビリティの高いクラウドサービスが適しています。
コスト面だけでなく、自社のIT部門の対応力やセキュリティ要件も考慮して選定することが大切です。
ステップ4:データの取り込みと変換プロセスの設定
データレイクにデータを取り込むためのETL(抽出・変換・読み込み)プロセスを設計します。
データの取り込み方法は、一定期間ごとにまとめて処理する「バッチ処理」と、リアルタイムで処理する「ストリーム処理」があり、データの種類や用途に応じて選択します。
製造現場では、生産ラインのセンサーデータなど即時性が求められるものはストリーム処理、月次の生産実績などはバッチ処理というように使い分けると効率的です。取り込んだデータは必要に応じて加工し、データウェアハウスへ送るための変換プロセスも設定しておきます。
特に異なる工場間でデータ形式が統一されていない場合は、データの標準化も重要な作業となるでしょう。
ステップ5:セキュリティ対策とデータガバナンスの確立
製造業では機密性の高い生産技術データも扱うため、適切なセキュリティ対策が不可欠です。
データへのアクセス権限を適切に設定し、重要データの暗号化やアクセスログの記録など、セキュリティ面の対策を講じることが重要です。また、データの整合性を確保するためのルールや、誰がどのデータに責任を持つかを定めたデータガバナンスの体制も整備しましょう。
製造現場では複数の部門がデータを利用するため、利用権限の一元管理も重要なポイントとなります。
データレイク導入後は、実際の運用を通じて問題点を発見し、PDCAサイクルを回して継続的に改善していくことで、自社に合ったデータ活用基盤が完成していきます。
製造業におけるデータレイク導入時の3つの注意点
製造業でデータレイクを導入する際は、注意点として以下3つのポイントを確認しておきましょう。
- 目的設定と事業戦略の策定
- ガバナンス体制
- 専門人材の確保と適切なリソース計画
順番に解説していきます。
注意点1:目的設定と事業戦略の策定
データレイク導入前に、製造業の経営者として「何のためにデータを集めるのか」という目的を明確にすることが最重要です。
漠然と「データを活用したい」という思いだけでは、何を収集し、どう活用するかが定まらず、プロジェクトが迷走してしまいます。まずは自社の製造現場における具体的な課題(品質向上、生産効率化、設備保全など)を特定し、解決に必要なデータは何かを洗い出しましょう。
「データレイクを作ること自体が目的」となってしまうと、多額の投資をしても成果が得られなくなる危険性があります。
製造現場のデータを収集する際は、生産ラインごとの課題や工場間の連携における問題点など、具体的な業務課題と紐づけることが成功への近道となるでしょう。
注意点2:ガバナンス体制
データレイクは、その名前とは裏腹に、管理が不十分だと「底なし沼」と化す危険性をはらんでいます。
製造業の現場では様々なセンサーデータや生産記録が発生するため、時間の経過とともにデータが肥大化し、「誰が何のために保管したデータなのか」が不明瞭になりやすい特徴があります。データの重複や不整合が増えると、後々の分析時に多大な労力やコストが発生し、場合によっては分析自体が不可能になることも珍しくありません。
この問題を防ぐためには、データの保存ルールを明確にし、メタデータ(データに関する説明情報)の管理を徹底する必要があるのです。
製造業特有のデータ(設備ID、製品コード、工程コードなど)の標準化と、定期的なデータクリーニングの仕組みを構築することが、長期的な活用には欠かせません。
注意点3:専門人材の確保と適切なリソース計画
データレイクの設計、実装、運用には高度な専門知識や特別な技術が必要であり、精通した人材が不可欠です。
製造業においては、ITの知識だけでなく製造プロセスへの理解も併せ持つ人材が必要となるため、適切な人材確保はさらに難しい課題となります。特に生データをそのまま扱うデータレイクでは、各種データの前処理やデータ統合のための高い技術スキルと強力なツールが求められます。
人材不足を補うためには、クラウドベースのサービスを活用したり、段階的に小規模から始めたりするアプローチが有効でしょう。
製造業の経営者としては、外部リソースの活用と社内人材の育成の両面から計画を立て、長期的な視点でデータ活用能力を高めていくことが大切です。
製造業におけるデータレイクの今後の展望
製造業のデータレイク市場は2030年に向けて年率22.40%という急成長が予測されています。
この成長を後押しするのは、世界のデータ量が163ゼタバイトに達するという爆発的な増加です。
製造現場では、
- 見積AI
- 生産計画AI
- 工程設計AI
など、様々なAI技術が実用化され、データレイクと連携した業務効率化が進むでしょう。
特に注目すべきは工場のIoTデバイスから生成される膨大なデータで、リアルタイム処理を通じた予測分析や品質管理の革新が期待できます。製造業経営者にとってデータレイクは、サプライチェーン全体の最適化による余剰在庫削減などの具体的効果をもたらす重要な投資となるはずです。
「2025年の崖」と呼ばれるDXの転換期を乗り越えるには、競争力維持のためデータレイク構築が不可欠な選択肢となっています。
まとめ
データレイクとは、多様な形式のデータを加工せずそのまま一元管理できる大規模なデータ保管庫です。
製造現場のセンサー情報から画像・動画まであらゆるデータを蓄積し、後から様々な分析に活用できる柔軟性が特徴です。
製造業におけるデータレイク導入のメリットは、以下のとおりです。
| メリット | 効果 |
|---|---|
| 工場間データ連携 | 複数工場の情報を標準化し生産効率を向上 |
| リアルタイム経営判断 | 現場の状況を即座に把握し迅速な対応を実現 |
| 柔軟なデータ活用 | 設備保全や需要予測など多角的な分析が可能 |
導入には目的設定、データの棚卸し、適切なストレージ選定、プロセス設計、ガバナンス確立の5ステップが重要です。
2030年に向けて年率22.40%の市場成長が予測され、AIとの連携による予測分析や品質管理の革新など、製造業の競争力強化に不可欠な基盤となるでしょう。