
日常業務において、AIを活用しようという動きが高まっています。すでにサーチエンジンや自動運転、お掃除ロボットなどで活用が広がっているAIですが、どのような手順で作成されているのでしょうか。
この記事では、AIモデルの基本的な知識と併せて、その種類や作成の流れなどについて解説します。
AIモデルとは
AIモデルとは、あらかじめ収集されたデータの中に存在するパターンや相関関係を学習し、その結果を活用して未知のデータに対して予測や判定を行う一連のプロセスのことを指した呼び方です。
AIモデルは「機械学習モデル」と呼ばれることが多くあります。「モデル」とは「型」という意味で、データを入力すれば、結果(出力)が出てくる仕組みを指します。画像や文章、数値などのデータが入力されたら、モデルによって事前に設定された解析方法でAIが解析を行い、判定や評価、文章、画像などの結果が出力される流れです。
AIモデルは、何に使うのかその使用目的によって作り分ける必要があります。実用化するまで複数の既存モデルを使用したり、新たにモデルを構築したりして最善の結果が得られるよう、試行錯誤を繰り返します。このように、1つのAIモデルができるまでには多くの時間と労力が費やされています。
AIモデルとアルゴリズムの違い
入力されたものから何かを出力しようとするとき、アルゴリズムという言葉もよく聞きます。AIモデルとアルゴリズムはどのように違うのでしょうか。
アルゴリズムとは、入力から出力するまでの「方法」を指した言葉です。処理、判断(真か偽か)、出力といった「方法」ですので常に決まった方法に従って出力されます。一方、AIモデルはその「方法」で得られた結果、すなわち「経験」を積み重ねた「知識」です。
例えば、道路上の人や自動車、標識などの対象物画像のデータとその名前を入力し関連付けるアルゴリズムを繰り返し行ってAIモデルを作成すると、カメラに映った画像から映っているものは何かを判別できるようになります。
このように、AIモデルはアルゴリズムに従って実行された結果を積み重ねて学習を繰り返し、訓練されます。学習が進んで知識が積み重なれば、次第に未来の予測などができるようになります。
無料eBook
-
 図版と事例でわかる|製造業DXの教科書
図版と事例でわかる|製造業DXの教科書世界市場での競争の激化や労働人口の減少などが進む今、日本の製造業においてDX(デジタル・トランスフォーメーション)の推進は不可欠です。 このeBookでは、製造業のDXの全体像について詳しく解説します。 DXに必要な技術を製造プロセスごとに紹介するほか、具体的な活用事例、製造業DXの今後の展望まで幅広く理解できる内容になっています。
AIモデルの種類
AIモデルはその学習方法によっていくつかの種類に分類されます。ここでは、一般的な4つのAIモデルについて解説します。
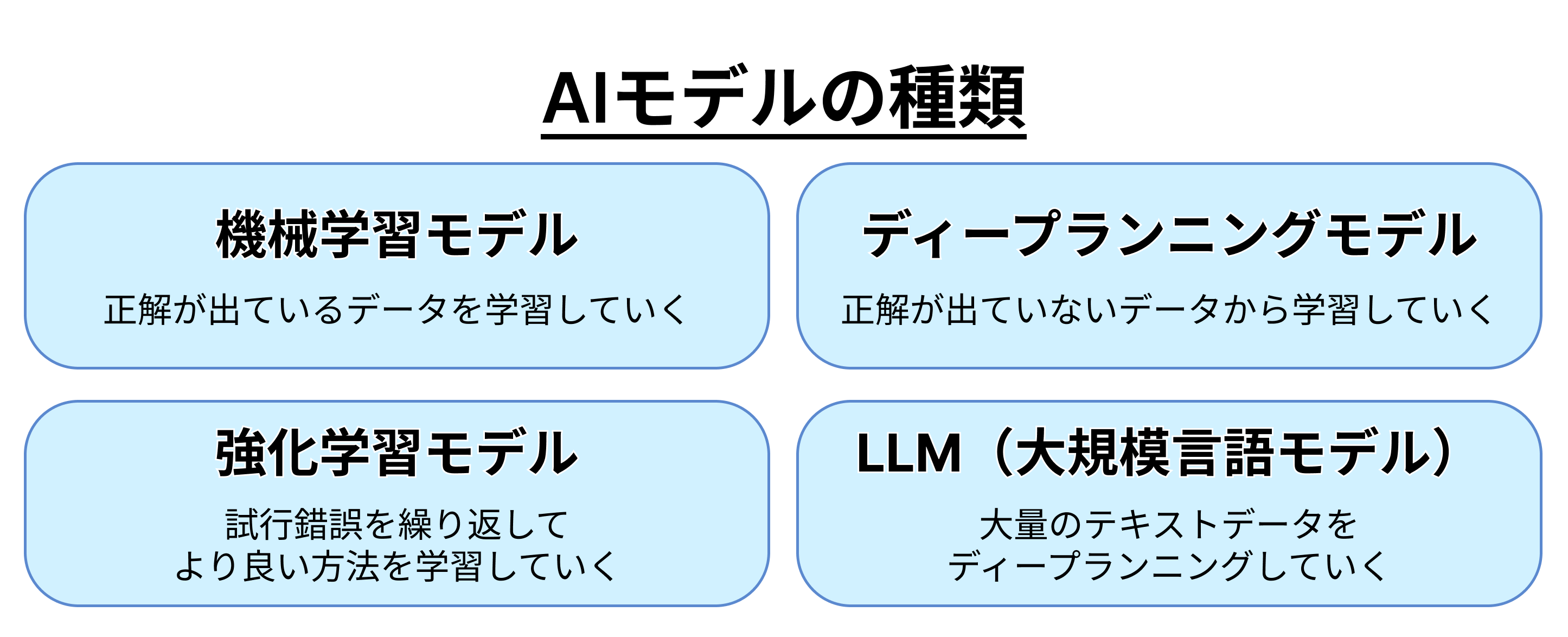
機械学習モデル(教師あり学習)
機械学習モデル(教師あり学習)とは、正解が付されたデータを学習していく方法です。例えば、猫の画像に「猫」というラベルをつけて入力します。その画像の中から猫とはどのような形でどのような色なのかなど、そのパターンを学習していきます。
また、教師あり学習は回帰モデルと分類モデルの2つに分けられます。回帰モデルは連続した数値の法則性から将来の数値を予測するモデルです。金融や気象の予測などに用いられます。
さらに回帰モデルは、線形回帰と多項式回帰に分けられます。線形回帰は単回帰ともいい、線形の単純な関数と計算式で表されます。多項式回帰は二次関数、三次関数など非線形の分布で表します。
分類モデルは、入力データを答えで振り分けるモデルです。正解か不正解か、真か偽か、晴れ・曇り・雨・雪など複数の回答に振り分ける際に用いるモデルです。
教師あり学習は、人間が結果を与える学習方法であるため、学習精度が高く学習の速度も速くなる点がメリットです。一方、正解がないデータがある分野や、データの質に影響される分野には応用しにくい側面もあります。
ディープラーニングモデル(教師なし学習)
ディープラーニングモデル(教師なし学習)は、正解はなくAIにデータのみを与えて、それらのデータの共通点を探し出し、ある1つの事柄を学習していく手法です。発見された共通点について、人間がそれは何を示しているのかを入力していきます。
また教師なし学習は、クラスタリングとアソシエーション分析という2つの手法に分けられます。クラスタリングは、データ群を分類できる基準を見つけ出す方法です。散布図を描けばデータの固まりが見えてきますが、これが複数あった場合に分類していきます。
アソシエーション分析は、大量のデータの中から2つの事象の発生件数の関係性から関連性を見つけ出してパターンを見つけ出す手法です。例えば、タイヤチェーンを買った人は手袋も同時に買うなどの法則性を見つけ出します。
教師なし学習は、一つひとつのデータに正解を入力する必要がないにもかかわらず、法則性を見つけ出せるところがメリットです。しかし、そのようにして見つけ出された法則が必ずしも正しいとは限らないため、人間による検証が必要です。
強化学習モデル
強化学習モデルとは、AIが自ら試行錯誤を繰り返してより良い方法を学習していくモデルです。良い結果には良い評価を与え、これを繰り返して最適な方法を学んでいきます。
この方法は、YESかNOのような2者択一的な正解はなく、何かより良い方法があるはずだというシチュエーションに有効です。人間でいうと経験を積ませる方法に近いといえます。ただし、コンピュータですので人間よりはるかに速く経験を積むことが可能です。
AIは大量のトライアンドエラーを繰り返して、その都度結果についての評価を記録していきます。そして膨大な経験の中から、最も良い結果を得るにはどのようにしたら良いかを導き出せるようになっていきます。
お掃除ロボットは、壁やテーブルの脚などの障害物に軽くぶつかりこれを繰り返すことで、部屋の状態を知り最適な掃除ルートを学習していきます。ユーザーはロボットに部屋の間取りなどを教えなくてもよいのです。このほか、自動車の自動運転、将棋や囲碁、ロボットの歩行制御なども強化学習モデルの応用例です。
LLM(大規模言語モデル)
LLM(大規模言語モデル:Large Language Models)とは、大量のテキストデータをディープラーニングという方法で学習するモデルです。言語の形式を成している文章の単語の並びには文法があります。大量の文章を入力して並び方を学習すれば、自然な単語の並びの発生確率が高いことを学び、逆に意味のない単語の羅列は発生確率が低いことを学びます。
例えば「運動」という単語の後には「する」の活用形、「すれば」「したら」などが来ることを予測することができるようになります。こうしてトレーニングしたものを自然言語処理モデルといい、トレーニングの仕方を変えることで、感情分析、文章要約、質問応答などさまざまなタスクに適応させられます。
LLMは、インターネットとコンピュータの処理能力を活かして、従来の自然言語モデルよりも計算の量やデータ量、処理するパラメータ数を巨大化させている点に特徴があります。ChatGPTなどがLLMにあたりますが、もはや人間と自然な会話が可能なレベルにまで発達しつつあります。
マルチモーダルとシングルモーダル
さまざまなAIモデルについて紹介してきましたが、これまでのAIは機械学習の対象となるデータが、映像、テキスト、数値など単一種類のデータに限られていました。これに対して、映像と音など複数種のデータを組み合わせて判断ができるように学習するAIをマルチモーダルAIといいます。
モーダルとは入力情報の種類のことです。複数の種類のデータを組み合わせるマルチモーダルAIは、シングルモーダルAIではできなかったことを可能にします。例えば、防犯カメラで2人の人物が話をしている映像があったとすると、AIで迷惑行為や危険を判断していたとしても正常にみえるでしょう。ところがここに音声データが加わり、2人の人物が激しく言い争いをしていることが分かれば、これはアラートを出す対象になり得ます。
このように複数の種類の情報で総合的に判断できるようにしたものがマルチモーダルAIで、シングルモーダルAIより緻密で深い洞察が得られるようになります。言語で指示をして画像を生成するAIも話題を呼んでいますが、これもマルチモーダルAIの一種だといえます。
AIモデル作成の流れ

AIを業務に活かすにはそれに見合ったAIモデルの作成をする必要があります。ここでは、AIモデルを作成する際の流れについて、データ収集、データ加工、モデル構築、評価と再学習に分けて解説します。
データ収集
AIモデルの完成度は学習に使用されるデータの品質と量によって決まります。AIモデルは、「無知の状態」から構築を始めなければならないので、より多くのデータを学習していくことが重要になるのです。
ただデータを集めればよいということではなく、正しく抜けがない正常なデータでなくてはなりません。例えば、なにかの温度の観測データであれば、しかるべき場所で、しかるべき装置を用いて、正しいタイミングで抜けることなく正しく計測されたデータである必要があります。画像データであればしっかりと学習の対象物の写ったデータが多く含まれていなければ意味がないでしょう。
AIが普及し始めてから、無料のデータセットなども手に入りやすくなってきました。また、有料のデータセットも提供されています。基本的なデータセットはそれらを活用して、自社でしか発生しえないデータなど、集めなくてはならないものだけを収集しましょう。
データ加工
データの収集が終わったら次はデータの加工に移ります。データの加工は「アノテーション」と呼ばれており、テキストデータや音声データ、画像データに「タグ」と呼ばれる目印をつけていく作業です。
機械学習は、学習するデータが何であるかを認識するのにタグが必要です。タグのついた大量のデータを読み込みながらアルゴリズムを学習していきます。
アノテーションが不正確、不完全だと正しく完全なAIモデルはできません。そのためアノテーションは重要な作業になります。
モデル構築
データにタグをつけるアノテーションが終わったら、AIモデルを構築していきます。画像認識や音声認識、データ認識など、どのような用途にAIモデルを活用するのかによって構築するモデルの種類は変わります。
また、一度できたモデルはトレーニングを繰り返して精度を高めていきます。例えば画像から製品上の傷をチェックするAIモデルを作ろうとしている場合は、わずかに傷がついた製品の画像を大量に読み込ませて訓練をしていきます。こうしてAIモデルを、業務で活用できるレベルにまで育てていきます。
評価と再学習
AIモデルは使い続けるうちに、新製品が出るなどして中身を変えていかなければならなくなります。また、社会環境の変化によってAIモデルの予測が当たらなくなってくることもあるため、定期的に評価して再学習をしていかなければなりません。
このように、AIモデルを老化させずに進化させ続ける考え方は、MLOps(機械学習基盤)といいます。AIモデルは簡単に作り直せるものではないので、作動精度を高い状態で維持するための評価と再学習は重要です。
まとめ
機械学習や自然言語処理技術を基に構築されたAIモデルは、製造業においてもさまざまな局面で効果を発揮できる可能性があります。品質管理や生産プロセスの最適化、あるいは画像認識や異常検知を行うモデルなど、不良品の早期発見や製造プロセスの効率向上に寄与するでしょう。
また、LLMも製品のマニュアル作成や保守作業支援に役立つことが期待できます。大量の技術文書やデータを学習させれば、効率的な情報提供が可能となるでしょう。またそれを活用した、質問応答型のモデルの作成も考えられ、社内の知識共有と業務の迅速な進行に役立ちます。
【こんな記事も読まれています】
・【会員限定動画】サプライウェブで実現するマスカスタマイゼーション時代の企業戦略
・製造業における購買・調達業務とは?課題の解決方法も紹介
・ビジネスや技術のトレンドに反応しながら進化を続けるCRMの事例を紹介